Aug 2021 -Extracting and diffing Microsoft patches in 2021
Every month, we generate files from the Microsoft Patches, statically analyze them and provide an overview of the changes. This allows interested parties to quickly analyze vulnerabilities or functional changes and gain actionable insights. By enriching files and functions with annotations, our user base can profit from expert knowledge and contribute back to the community.
In this post, we walk through the recent CVE-2021-34527, dubbed PrintNightmare and demonstrate how we can get an overview of the vulnerability:
From the Microsoft Update Guide, we know that the vulnerability is located in the spooler service and patched by the July patchset.
Starting from the files.ninja overview of the July patchset, we filter the list of patched binaries by constraining the applicability to "Printing".
In the resulting list of binaries, we select the file called "spoolsv.exe", because it sounds like a promising entry for our analysis.
This takes us to the comparison overview for the latest patch difference.
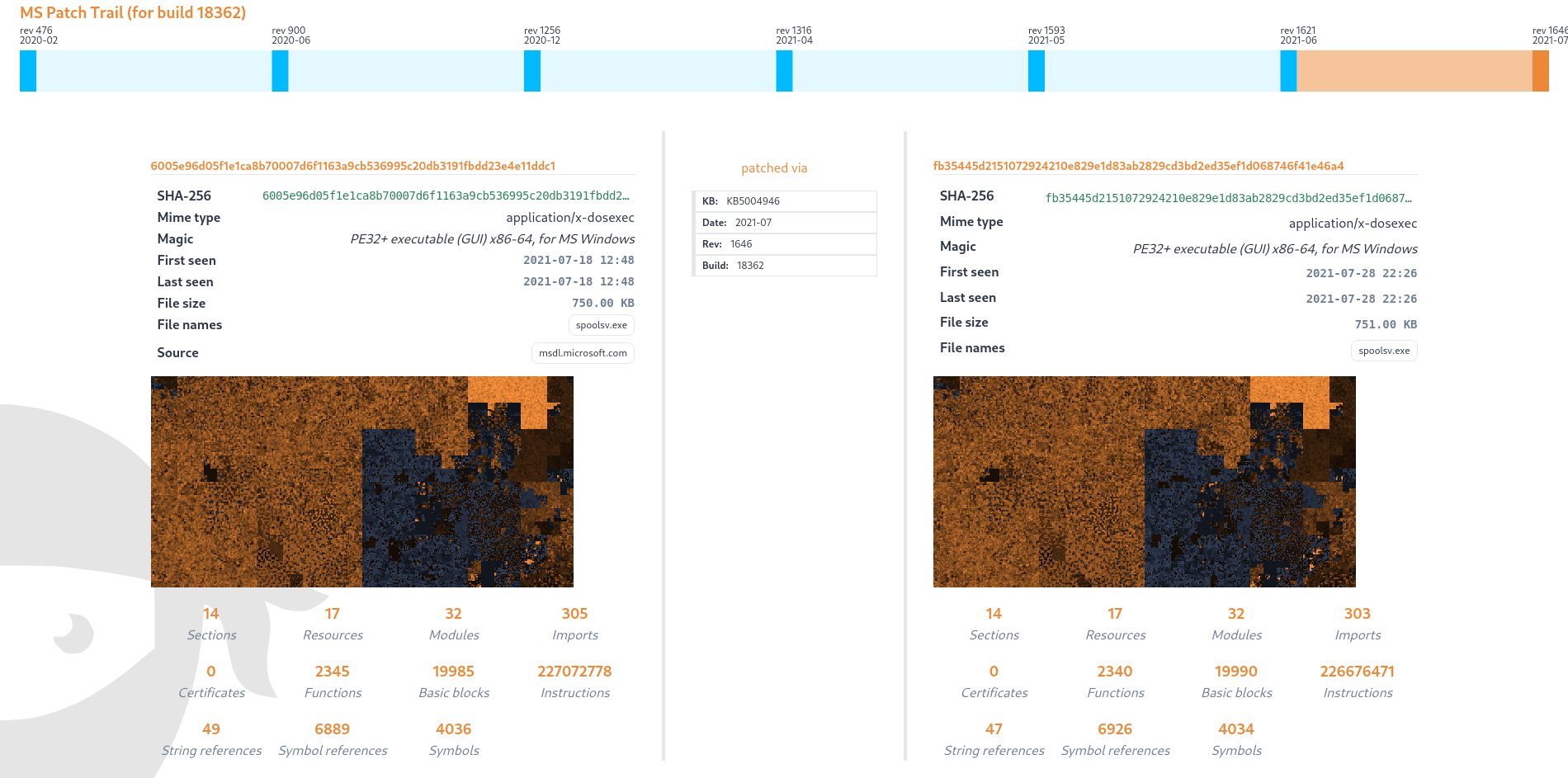
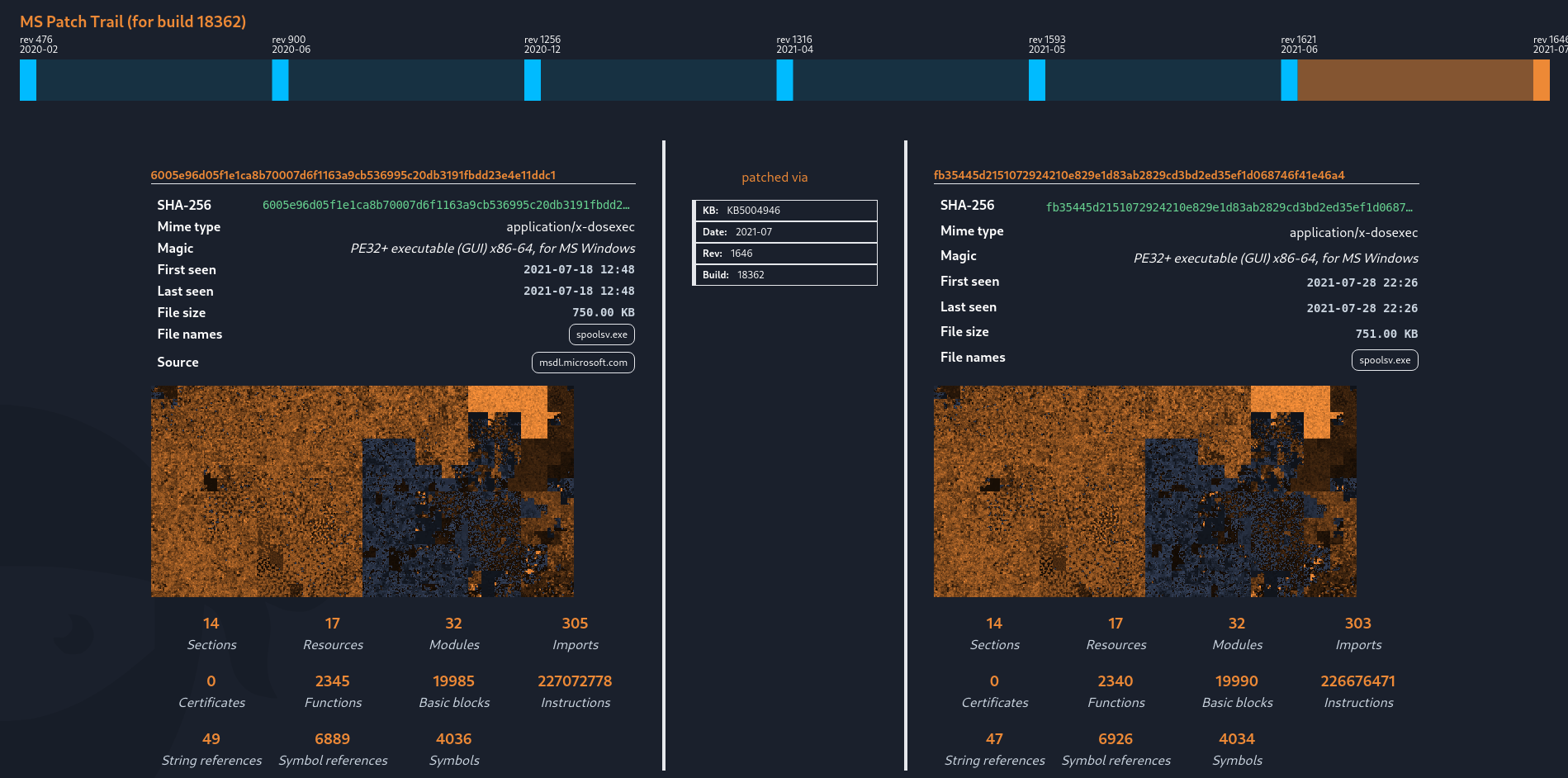
In the function mapping, only some named functions are considered to differ between the two releases. From the Microsoft description of CVE-2021-34527, we know that the CVE is caused by being able to remotely install signed and unsigned printers. Among the patched functions, we can find RpcAddPrinterDriverEx. Opening these functions in new tabs renders a disassembly graph and gives us the option to attempt decompilation. The decompilation reveals that the function has gained additional checks in the form of calls to a function named "RestrictDriverInstallationToAdministrators".
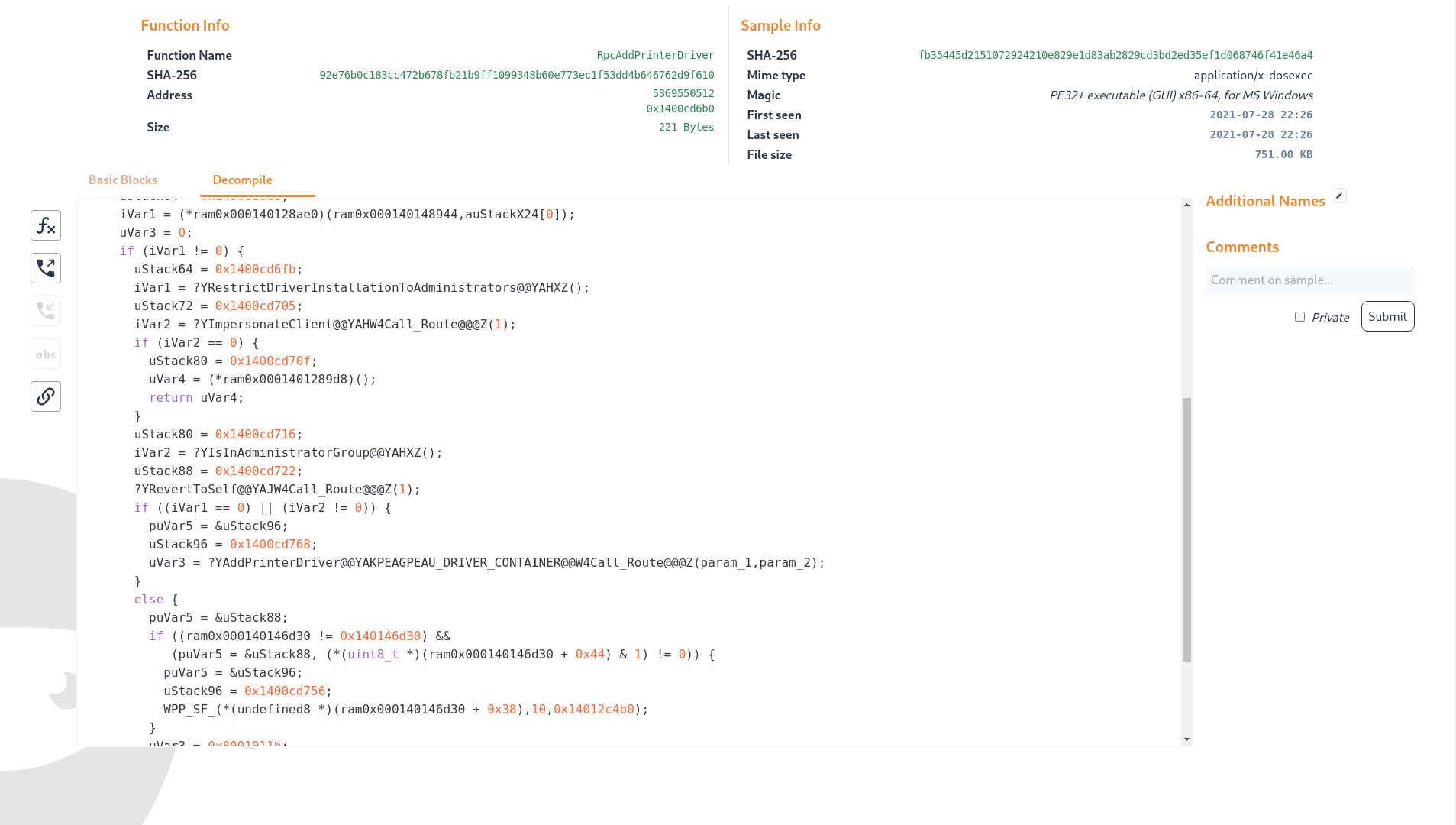
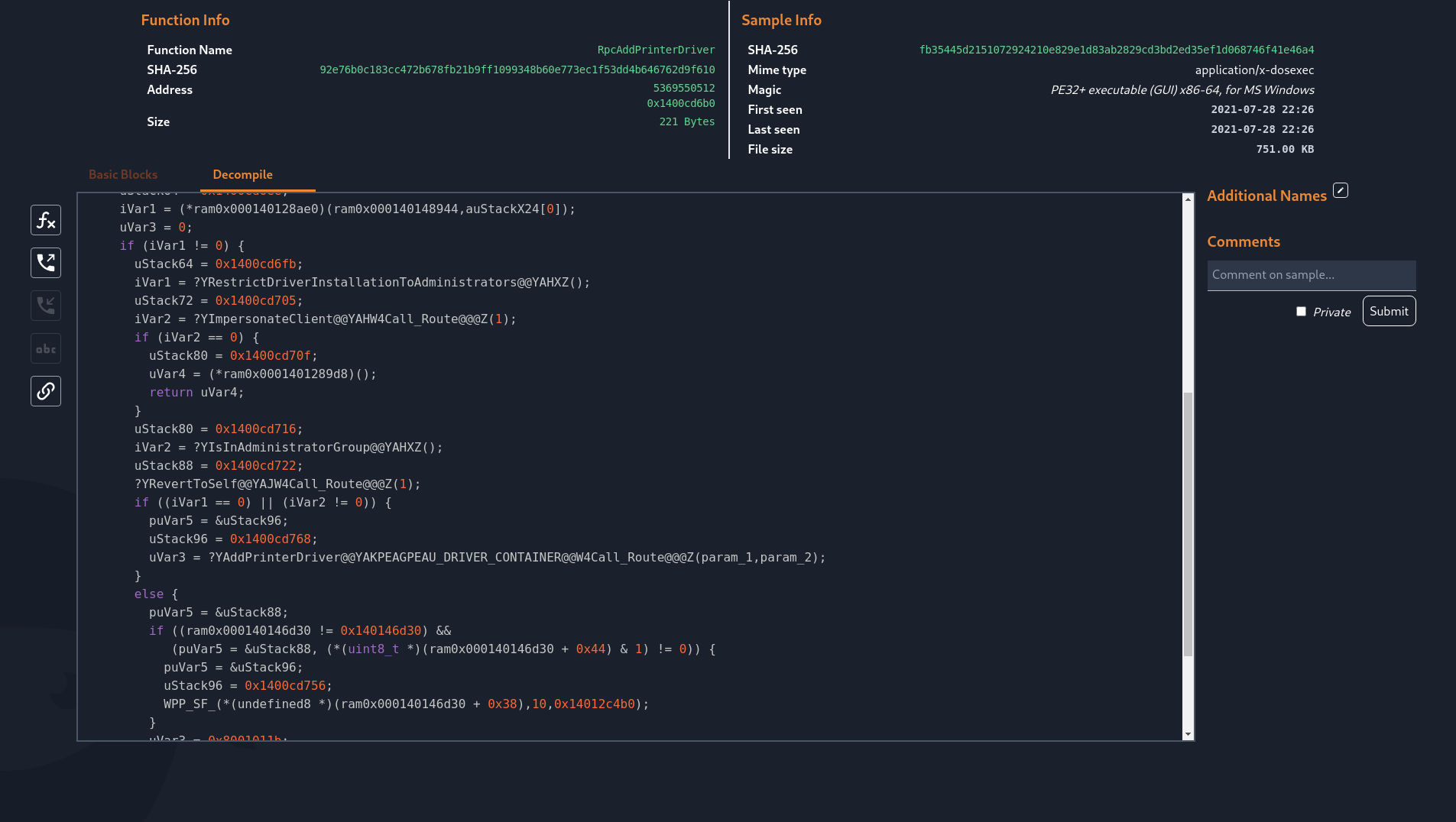
In a few clicks we have arrived at the exact patch we were looking for. We can continue analysis from here by downloading the files from Microsoft’s symbol servers and loading them into our favourite reverse engineering tool or start to code up a proof of concept attempting to hit this specific code path. Can you now find CVE-2021-36958 in the August patch set?
Jan 2021 - And we are live
After more than 10 years of playing CTF competitions and software engineering it was time to put some of our tools to use for a wider audience. We attempted to distill these tools into an API-focused platform and website that makes it easy to dissect files - and most importantly - compare them against a large collection of files in order to find similarities.
At the heart of files.ninja is the custom file processing pipeline that analyzes executable files and their code inside by detecting functions and extracting the overall callgraph. This pipeline is combined with a data model and search engine that allows to detect overlaps and similarities with any other files.
Currently, you can upload a file and look at its file format metadata and structure, as well as a list of functions that were extracted.
When the file is fully analyzed a similarity search is triggered automatically and any search results with a high enough score will be displayed. For these similar files a "function alignment" is provided, which maps matching functions of the two files to each other.
This is an area where we would like to improve the visualization and UI and have a few ideas for the next few sprints already. Any feedback is welcome!
If you’re interested in a specific function of a file - or an aligned pair of functions - the site can render a graph representation of the function’s basic blocks right in the browser.
Each function view also let’s you pivot to called functions (calls) and functions that call the currently displayed function (callrefs).
Beyond the individual file analysis and similarity engine, all file and function metadata is indexed in an Elasticsearch cluster and thus searchable across all uploaded files. This lets you search for files with a tag, files that contain a specific function (by normalized hash) or files that have a function that uses a unique string.
As you might have caught in some of the videos, we also let you tag, comment and name files and individual functions. This is something we use heavily in analysis workflows and it helps categorizing files - but of course this becomes more powerful the more people actually use the site and tag or name things.
Oh and of course it has light mode :)
And after all this we decided to put the site online - to start collecting feedback, thoughts and ideas from friends and colleagues - well and Twitter.
So far we’re still only scratching the surface of what is possible with this platform and there already is a long list of additional features on the roadmap - some of the most important ones (in our opinion) are:
- Static linking analysis/detection: Right now we focused on similar files - but it is fairly straightforward to extend our engine to detect when a file is basically contained / embedded in another one - so for example if a file statically links OpenSSL.
- Bindiff (function level): We already have a "diff" to a certain extent on the whole file level - but we would like to extend this to provide both a binary diff and function call graph diff view.
- File relationships / tree similarity: Right now files are compared just to each other. We implemented the Dex file format (Android apps) but of course it’s of limited use to compare individual dex files. Ideally we would compare the whole APK against another APK, summarizing the content similarity across all contained files (in the zip). This is tricky / costly but of course can be very powerful.
- Grab executable code from dynamic analysis memory: When trying to use the platform against packed files it of course quickly stops being useful due to its static nature. We would like to execute files and extend our analysis pipeline to actually executed code.
As you can see we still are not anywhere close to being done. Let us know your feedback and tell us if you find this useful via team at files.ninja or Twitter.